Algorithmic Confounding in Recommendation Systems
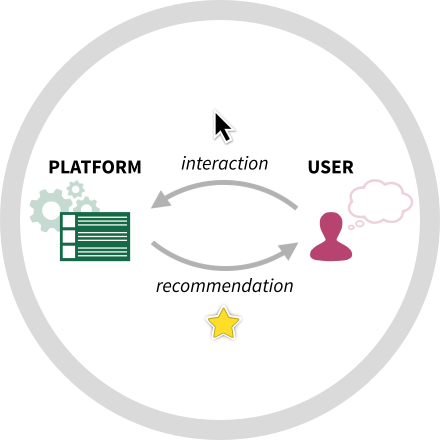
Recommendation systems occupy an expanding role in everyday decision making, from choice of movies and household goods to consequential medical and legal decisions. The data used to train and test these systems is algorithmically confounded in that it is the result of a feedback loop between human choices and an existing algorithmic recommendation system. This active project involves exploring the impact of algorithmic confounding in this context.